


The Mind Stone
You know you are getting old when your friends ask you about the last movie you watched and your synopsis sounds like this:
“I saw that movie, you know the movie, with that guy who was in that romcom that was on TV the other day. It’s about that famous lawyer. That girl is in it as well, what’s her name again?”.
Memory may be more fundamental than we think with regards to how our minds work. The ability to recall enables us to form associations in the face of regularities in our environment. The peculiarities of how our memory functions may be the reason for the development of intelligence as the ability to predict one’s environment and the consequences of one’s actions (see for example Jeff Hawkins’ On Intelligence).
Two of these peculiarities are hardly accounted for in computational models of memory.
The first one is the ability we have to recall something indirectly, like when you are trying to remember some actor’s name. You start remembering what movie she was in, then think of that movie’s poster, and maybe that gives you a clue about an initial or a sound. Each association gets you closer to complete recall.
The second peculiarity is our propensity to see patterns everywhere or fill in the blanks, as it were. It is very useful when incomplete or mangled information is presented to us. Yuo cna porbalby raed tihs esaliy desptie teh speillgn msitkaes. It could also be the creative experience of seeing patterns in otherwise random stimuli (or “finding Jesus in the toast”).
Sparse Distributed Memory
However, one mathematical model of long-term memory that accounts for these peculiarities, which are in fact a direct consequence of how the model works, does exist. The Sparse Distributed Memory (SDM) model was introduced by Pentti Kanerva in 1988 in a tiny book, the brilliance of which I cannot stress enough. It all rests on the properties of the mathematical space of very large binary strings.
If you are able to turn data into very large binary strings (hint, hint) then each data point can be considered as a point on the surface of an n-dimensional sphere of radius sqrt(n)/2 where n is the length of these binary strings.
This “sphere” has the remarkable property that from the perspective of any particular point p in it (an n-dimensional vector), the rest of the space is nearly orthogonal. Take the similarity of two vectors p and q to be the cosine of the angle between them and you will see that if p and q are orthogonal to each other (i.e. perpendicular) their similarity is 0. The orthogonal property then implies that if we choose two points in the binary “sphere” at random they are very likely to be dissimilar.
A very simplistic account of how the model works is:
Inputs are binary patterns of length n, as we have seen (say, 256 bits). Addresses are also themselves binary strings, possibly of different length m, used to write to and from the memory. The “sparse” in the name of the model refers to the fact that we a-priori select only a sparse set of all the possible addresses we could have (two to the power m), which drastically reduces the amount of resource we require for implementing the memory.
Storage of an input X at address A occurs by writing X at all the addresses that are within a certain distance r from A, that is, all address locations that differ by, at most, r bits from A (this is the distributed part in the model’s name).
To read from memory at address A, you select a number of addresses that are within distance r to A and return essentially an average of all the values found at those addresses.
When we use input words to also correspond to addresses we can see how SDM can model the two peculiarities we discussed earlier. If you present the memory with an address that is only partially similar to one that has previously been written to (perhaps the binary string was corrupted by transmission noise), given certain constraints, you can use the averaged output as the next address to input to the memory and keep following this chain until you converge to an address/value very close if not equal to the original address/value. This is equivalent to indirect recall.
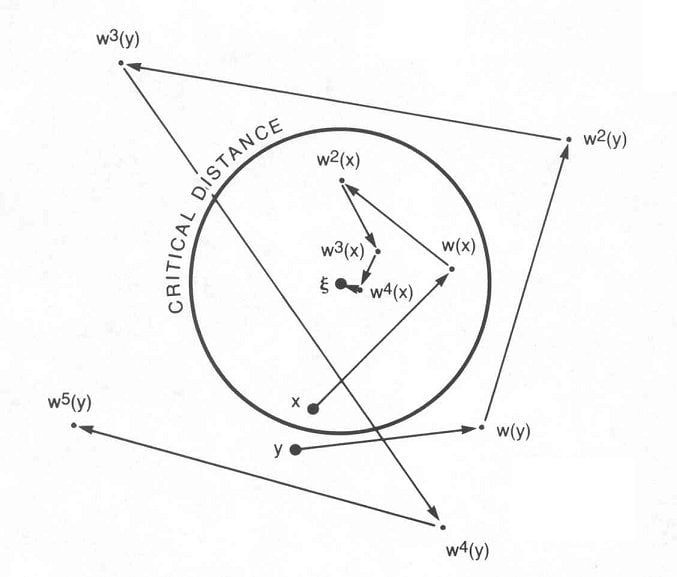
Also, if we supply an input address that the memory has never used, there may still be values stored in addresses that are r-close to it and, therefore, the memory will still return as output an average of these values, equivalent to Jesus-in-the-toast.
Hashing objects into large binary strings is, therefore, fundamental in harnessing the Mind Stone’s power. We can appreciate this power applied to languages next.
Random Indexing
In fact, the simplest binary hashing possible can be exploited to turn SDM’s binary “sphere” into a language recogniser as discussed in Joshi, Halseth, Kanerva 2015.
The simplest hashing would be to associate to each letter of the alphabet a random, long (10,000 bits) binary string. Remember that with large n, any two random points on the “sphere” are likely to be orthogonal (dissimilar).
By combining hashed letters using simple algebra we can form representations of whole words, nay, whole documents! A corpus of documents in a specific language is, thus, tersely represented by a point in the binary “sphere”.
Using this strategy, one can generate a set of canonical vectors, one for each language to be supported.
The orthogonal property together with the encoding strategy will enable us to keep encoded documents in different languages sufficiently apart from each other whilst keeping documents in the same language relatively close.
Now, take a document you have never seen, encode it in the usual way and find the closest canonical vector: voila! You will likely find out which language the document was written in.
The Soul Stone
In Part 2 of this article we saw how non-cryptographic hashing is used to implement Bloom filters to speed up set membership operations, while dramatically decreasing the memory resources required.
There was, however, a cost to be paid in terms of an error factor that could be made arbitrarily small. The reason that the error can be made arbitrarily small is related to the fact that traditional non-cryptographic hashing functions are created to minimise collisions: different words should, as much as possible, never hash to the same value even if they look similar.
However, what if you want to peer into the soul of things, get to their core while preserving some of their properties, like only the Soul Stone can do?
Finding duplicates in data is fairly simple, at least when looking for perfect copies. Detecting imperfect copies, like misspellings or different re-wording of the same entity (for example, geographical addresses), is a whole different business.
Thankfully there are many measures that can calculate similarity between strings of text, like, for example, the Jaccard index. The issue is that their computation often requires cumbersome and resource-heavy string operations.
The Soul Stone-like power of Locality Sensitive Hashing (LSH) comes to the rescue. The idea is to hash strings of text into fixed size, numeric “fingerprints” that somehow preserve the similarity of the original entities so that we can perform duplicate detection on the fingerprints instead.
LSH functions are built to maximise collisions so that, unlike in traditional hashing functions, they will put similar inputs in the same “bucket”.
Their ability to preserve the essence of their input makes them perfect for applications like data clustering and nearest neighbour search.
Conclusion
In this three-part journey we have looked at Time, Space, Power, Mind, and Soul demonstrating, one hopes, that non-cryptographic hashing is a true Infinity Gauntlet of computer science and that it’s available to all of us poor mortals (take that, Thanos!). What will you do with all this power?